Minimal Mistakes is a flexible two-column Jekyll theme. Perfect for hosting your personal site, blog, or portfolio on GitHub or self-hosting on your own server. As the name implies — styling is purposely minimalistic to be enhanced and customized by you ![]() .
.
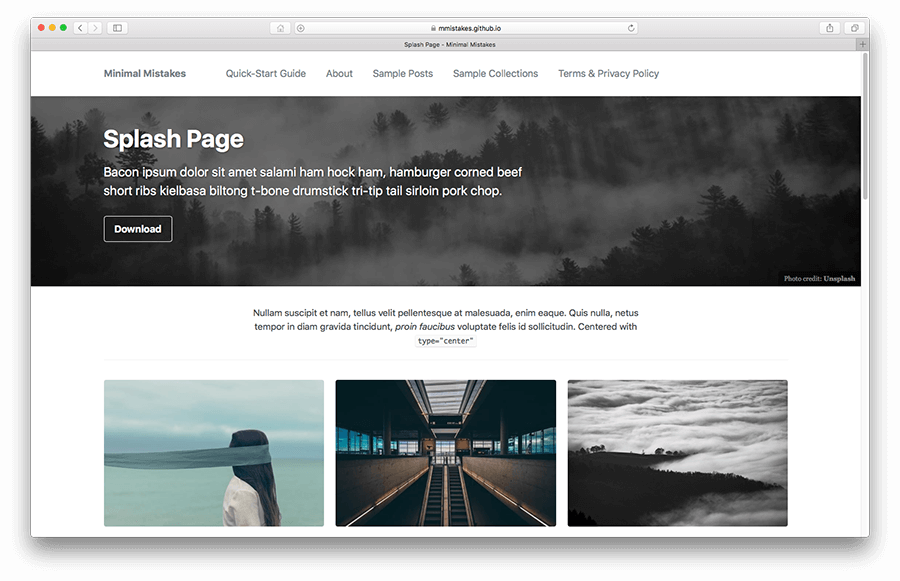

splash, single, and archive.
Notable Features
- Bundled as a “theme gem” for easier install/upgrading.
- Compatible with GitHub Pages.
- Support for Jekyll’s built-in Sass/SCSS preprocessor.
- Nine different skins (color variations).
- Several responsive layout options (single, archive index, search, splash, and paginated home page).
- Optimized for search engines with support for Twitter Cards and Open Graph data
- Optional header images, custom sidebars, table of contents, galleries, related posts, breadcrumb links, navigation lists, and more.
- Commenting support (powered by Disqus, Facebook, Discourse, utterances, giscus, static-based via Staticman v1 and v2, and custom).
- Google Analytics support.
- UI localized text in English (default), Arabic (عربي), Brazilian Portuguese (Português brasileiro), Catalan, Chinese, Danish, Dutch, Finnish, French (Français), German (Deutsch), Greek, Hebrew, Hindi (हिंदी), Hungarian, Indonesian, Irish (Gaeilge), Italian (Italiano), Japanese, Kiswahili, Korean, Malayalam, Myanmar (Burmese), Nepali (Nepalese), Norwegian (Norsk), Persian (فارسی), Polish, Punjabi (ਪੰਜਾਬੀ), Romanian, Russian, Slovak, Spanish (Español), Swedish, Thai, Turkish (Türkçe), and Vietnamese.
Demo Pages
| Name | Description |
|---|---|
| Post with Header Image | A post with a large header image. |
| HTML Tags and Formatting Post | A variety of common markup showing how the theme styles them. |
| Syntax Highlighting Post | Post displaying highlighted code. |
| Post with a Gallery | A post showing several images wrapped in <figure> elements. |
| Sample Collection Page | Single page from a collection. |
| Categories Archive | Posts grouped by category. |
| Tags Archive | Posts grouped by tag. |
For even more demo pages check the posts archive.
Credits
Icons + Demo Images:
- The Noun Project – Garrett Knoll, Arthur Shlain, and tracy tam
- Font Awesome
- Unsplash
Other:
- Jekyll
- jQuery
- Susy
- Breakpoint
- Magnific Popup
- FitVids.JS
- Greedy Navigation - lukejacksonn
- jQuery Smooth Scroll
- Lunr
Minimal Mistakes is designed, developed, and maintained by Michael Rose. Just another boring, tattooed, designer from Buffalo New York.