Running FAE
To run the FAE with intelligent embedding placement first we need to profile the embeddings based on available GPU memory.
Open run_fae_profiler.sh

You can change the available GPU memory by -hot-emb-gpu-mem
and the sampled inputs for profiling by --ip-sampling-rate
Run the fae profiler by
!./run_fae_profiler.sh
This step will segregate the training dataset into hot and cold parts with hot embedding dictionary.
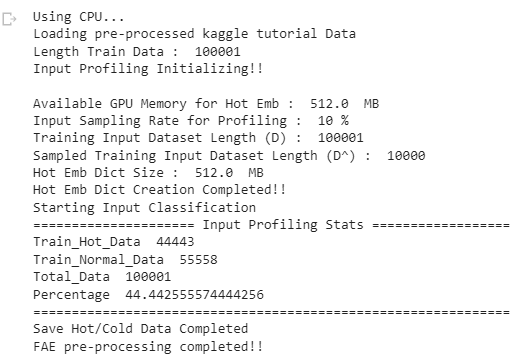
Observe the percentage of input dataset that only access the hot embeddings.
Now you can run FAE with segregated data and hot embedding placed on GPU by
!./run_dlrm_fae.sh
Observe the difference in Hot optimizer time and Cold optimizer time.